Xのおすすめを見ていて「RAGをゼロから実装して仕組みを学ぶ【2025年版】」という記事が面白かったので、Google Gen AI SDKの入門も兼ねて、RAGをゼロから実装してみました。もっとも、GoogleのAPIで実装してくれたのはAntigravityなのですが😅
まずはuvでサンプルコードのプロジェクトを作ってみる
uvを使ってターミナル上でサンプルコードのプロジェクトを作り、GoogleのAntigravityで開きます。Pythonのバージョンを3.13にしていますが、この記事を書いている時点で、Python 3.14ではstreamlitのインストール時にエラーが発生することが理由です。
cd <work-dir>
uv init --python 3.13 my-first-rag-app
agy my-first-rag-appAntigravitityのターミナル上で、パッケージを追加していきます。まずはサンプルコードが使っているopenaiパッケージをそのまま使います。
uv add streamlit numpy faiss-cpu python-dotenv openaimy-first-rag-appフォルダー直下に.envファイルを作って、とりあえずOPENAI_API_KEY= という1行だけ記述してファイル保存します。この時点でOPENAI_API_KEYの値は不要です。
.envファイルは.gitignoreに追加しておきます。uvが作成するデフォルトの.gitignoreに.envが含まれるとミスが減って良いのですが、、、
.env元記事の通りにdata/knowledge.txtとapp.pyを作成します。
この状態でapp.pyを動かすとstreamlitは起動するものの、OPENAI_API_KEYには値が設定されていないので、画面にはエラーメッセージが表示されます。
いったん、この状態でソースコードをCommitしておきます。後からOpenAI用のコードとGemini API用のコードを比較できます。
サンプルコードをGemini APIに変更する
この記事を書いている時点で無料枠のあるGemini APIを使うようにサンプルコードを書き換えます。無料枠の正確な情報はGoogle AIの公式ドキュメントで確認してください。
参考: 2025年12月3日時点での無料枠のレート制限 (既に古くなっています)
| モデル名 | RPM | TPM | RPD |
|---|---|---|---|
| Gemini 2.5 Pro | 2 | 125,000 | 50 |
| Gemini 2.5 Flash | 10 | 250,000 | 250 |
| Gemini 2.5 Flash-Lite | 15 | 250,000 | 1,000 |
| Gemini 2.0 Flash | 15 | 1,000,000 | 200 |
| Gemini 2.0 Flash-Lite | 30 | 1,000,000 | 200 |
- RPM: 1分あたりのリクエスト数
- TPM: 1分あたりのトークン数
- RPD: 1日あたりのリクエスト数
書き換えるのは手作業ではなく、AntigravityのAgentで行います。Agentのチャット入力枠はPlanningとGemini 3 Pro (Low)を選択した状態で、以下のようなプロンプトを入力します。@app.pyの部分はメンションです。@を入力するとファイル名を選択できます。
- あなたはRetrieval Augmented Generation(RAG)アプリケーション開発の専門家です。
- @app.py を`OpenAI`モジュールから`google`の`genai`モジュールに変更して、
Gemini APIを使って実装し直してください。
APIのパッケージは`openai`から`google-genai`に変わります。
- モデルは`gemini-2.5-flash`を使います。Antigravityがサンプルコードの修正を開始します。その間にGoogle AI StudioでAPIキーを作成します。
Antigravityの改修作業が終わるとAccept allボタンが表示されます。app.pyの変更点に異常を見つけられなければ、Accept allボタンをクリックして変更を承諾してください。
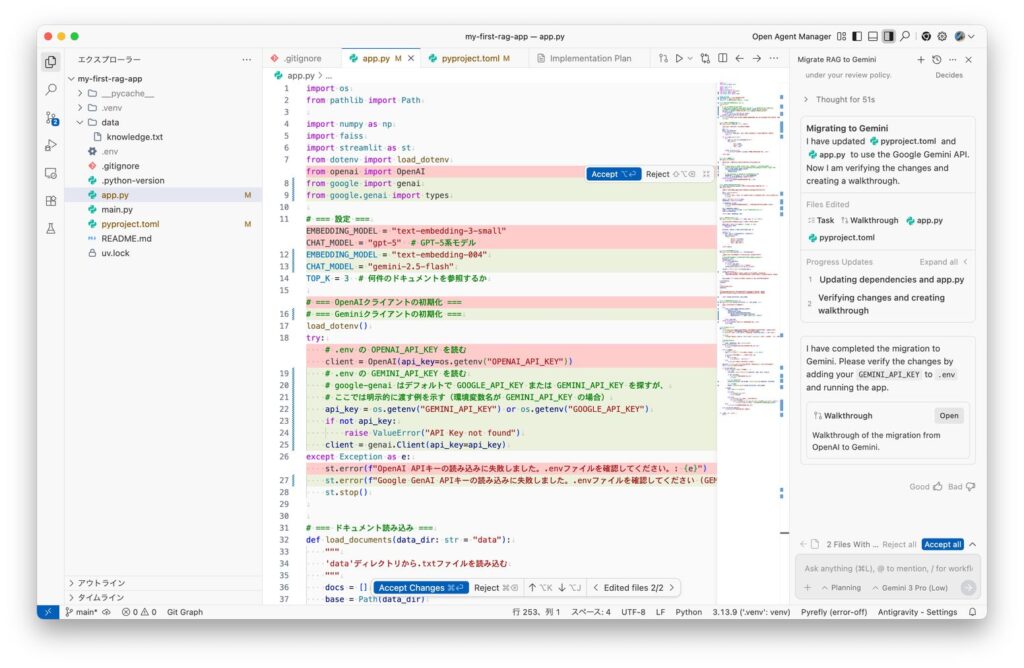
OPENAI_API_KEYはGEMINI_API_KEYに置き換わっていると思いますが、app.pyの変更内容を確認したうえで、.envファイルに環境変数名とGeminiのAPIキーを記述します。
GEMINI_API_KEY=<Google AI Studioで作成したAPIキー>実行します。
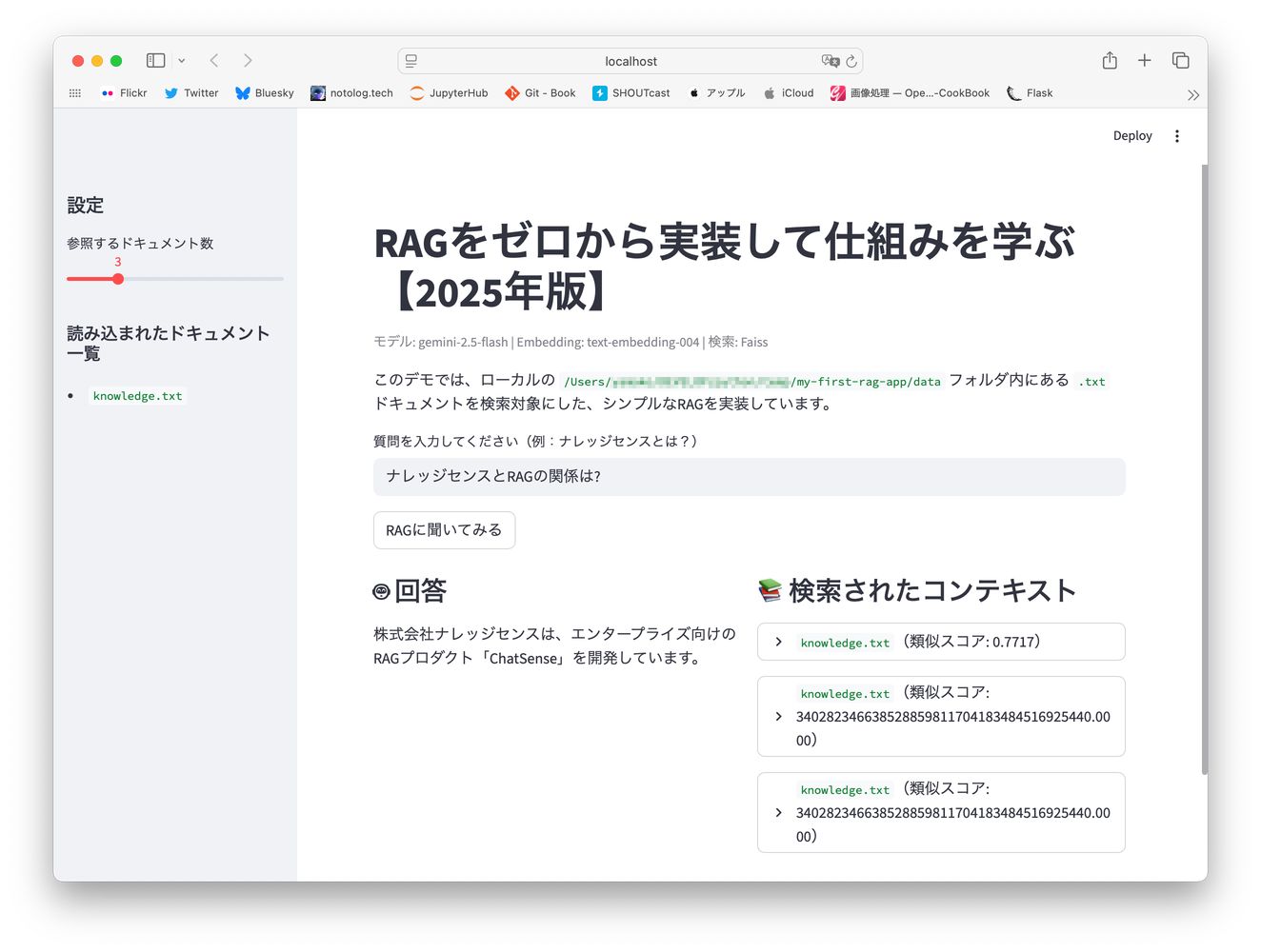
uv run streamlit run app.pygemini-2.5-flashを使ったRAGアプリケーションが無事に動作しました!
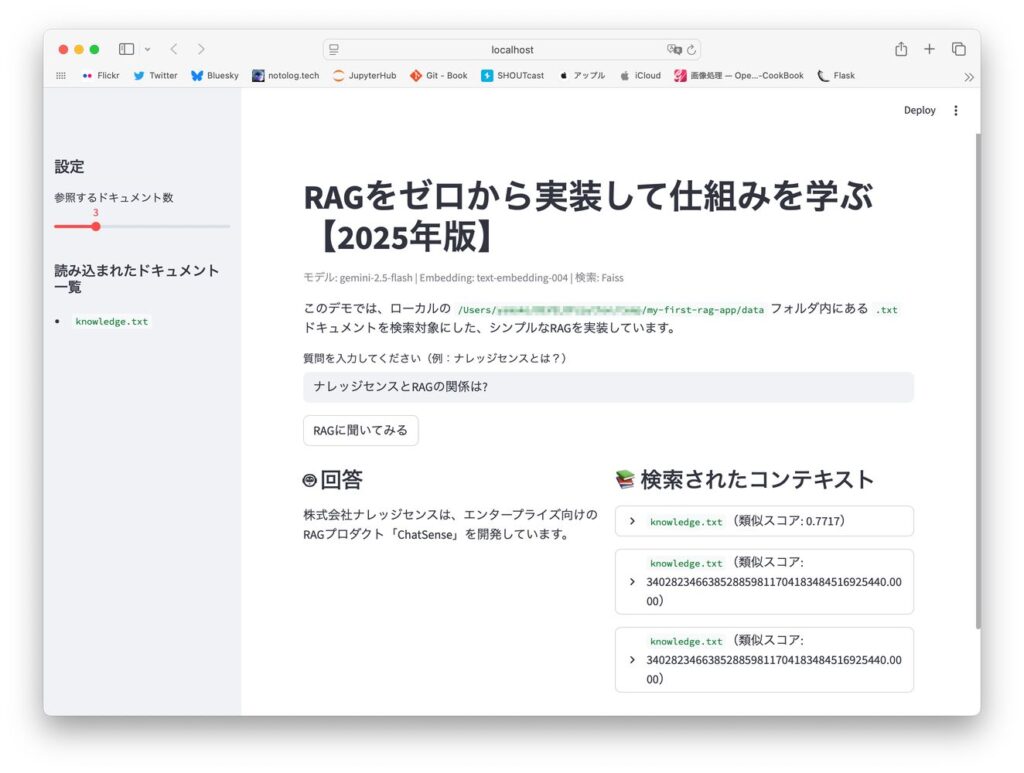
app.pyの実行画面dataフォルダーに自分の職務経歴書(Markdownの表形式)を入れて色々質問してみましたが、「Pythonを使った業務に携わっていた期間の合計は?」のような集計が必要になる質問にも答えてくれるので、これはとても便利です。
社内ドキュメントの職務経歴書に基づくと、Pythonを使った業務に携わっていた期間は以下の通りです。
(中略)
これらの期間を重複を考慮して合計すると、Pythonを使った業務に携わっていた期間の合計は**年**ヶ月です。
**の部分は業務期間の長さを計算して合計した数値が入っています。
RAGのサンプルコードをチャートにしてみた
Antigravityに実装してもらったapp.pyを理解するためにmermaidを使って処理の流れを(特に各関数のインプットとアウトプットが分かるように)整理してみました。
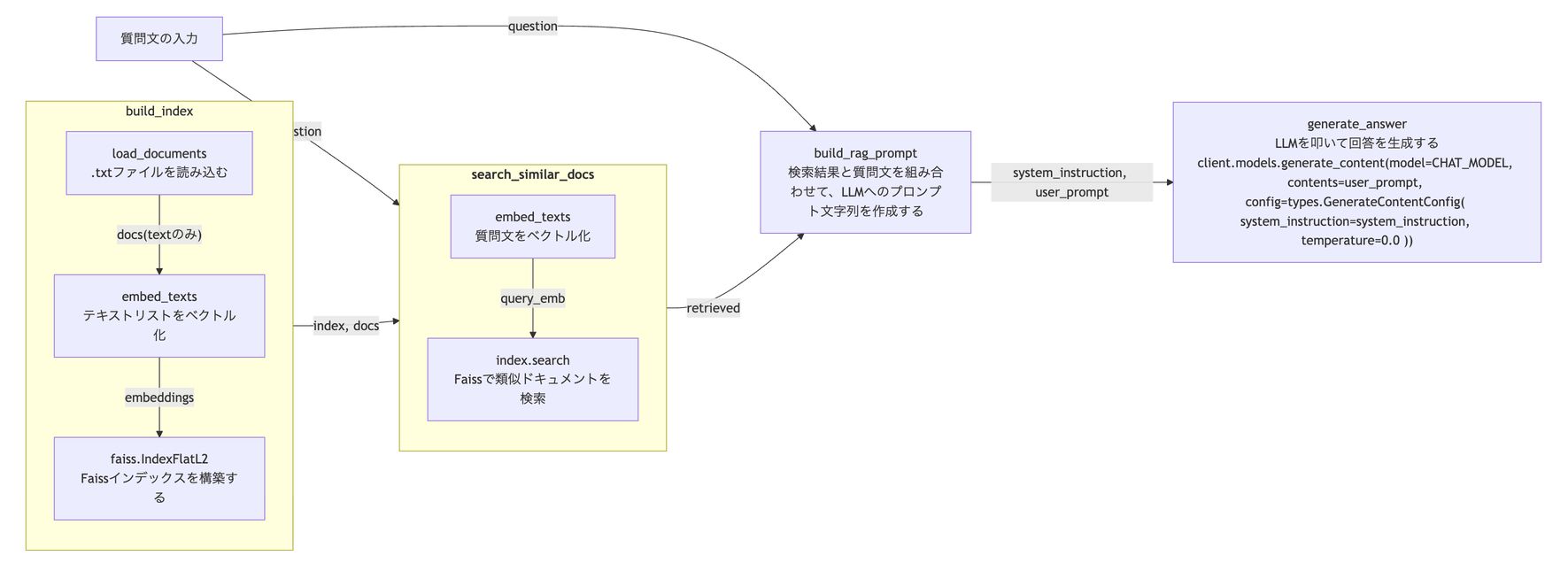
Gemini 3 Pro (Low)に処理の流れを解説をしてもらいました。
RAGという言葉を分解して、app.py の関数と対応させると以下のようになります。
- R (Retrieval: 検索)
- 役割: 大量のデータの中から、質問に関連する情報だけを探し出す。
- 関数: search_similar_docs
- これがないと: 全部のデータをLLMに読ませる必要が出てきます(データ量が膨大な場合、読みきれなくなります)。
- A (Augmented: 拡張)
- 役割: 検索で見つけた情報を、プロンプト(命令文)に付け加えて強化する。
- 関数: build_rag_prompt
- これがないと: LLMは検索結果を知らないままなので、ただの一般的な回答しかできません。
- G (Generation: 生成)
- 役割: 拡張されたプロンプトを元に、LLMが回答を作成する。
- 関数: generate_answer
generate_answer関数にはRAGでスコアの高かったテキストファイルの内容を全文渡しているので、長いテキストファイルの場合はload_documents関数の中で分割(チャンク化)するのが良さそうです。(と、Geminiからもコメントを貰いました)